CUDA 学习记录
从 Thread / Block / Warp / SP 的并行模型,到一维、二维全局坐标计算的入门笔记
· 9 min read
CUDA 并行实现 #
Thread —— 最小逻辑并行单元 #
CUDA 里的 Thread 可以先理解成最小的并行单元
比如这个 kernel:
__global__ void add_one(float* x, float* y, int n) {
int i = threadIdx.x;
if (i < n) {
y[i] = x[i] + 1.0f;
}
}
如果你启动 10 个 thread,那么每个 thread 都会执行这一段代码。
区别在于:
threadIdx.x
每个 thread 的值不同。
例如:
thread 0: threadIdx.x = 0
thread 1: threadIdx.x = 1
thread 2: threadIdx.x = 2
...
thread 9: threadIdx.x = 9
所以虽然所有 thread 执行同一份代码,但它们处理的数据不同。
这就是 CUDA 的基本思想。
为什么还需要 Block #
如果只有 Thread,会有一个问题:
一次 kernel 可能要启动几百万、几千万个 thread。
CUDA 不会把所有 thread 扔成一大坨,而是把它们分组,这个组就叫 Block。
可以理解成:
Thread:单个学生
Block:一个班级
Grid:整个年级
比如我们启动:
kernel<<<3, 4>>>(...);
意思是:
3 个 Block
每个 Block 里有 4 个 Thread
所以总 thread 数是:
3 × 4 = 12 个 thread
threadIdx.x 只是在 当前 Block 内部编号。
所以 Block 0 里面有一个 threadIdx.x = 0
Block 1 里面也有一个 threadIdx.x = 0
全局编号:
int i = blockIdx.x * blockDim.x + threadIdx.x;
其中:
blockIdx.x:当前是第几个 Block
blockDim.x:每个 Block 有多少个 Thread
threadIdx.x:当前 Thread 在 Block 内部的编号
假设:
kernel<<<3, 4>>>(...);
那么:
gridDim.x = 3
blockDim.x = 4
SM 是什么 #
Streaming Multiprocessor,流式多处理器,对应逻辑上的 Block(这里说的是,Block 是调度到 SM 上执行的单位)。
刚才讲的是 CUDA 的软件抽象,现在看硬件真实执行。
假设 GPU 有 2 个 SM
启动:
kernel<<<3, 4>>>(...);
也就是 3 个 Block:
Block 0
Block 1
Block 2
GPU 可能这样调度:
SM 0 执行 Block 0
SM 1 执行 Block 1
Block 2 先等着
等某个 SM 空出来后:
SM 0 执行完 Block 0
SM 0 再执行 Block 2
你不需要写:
Block 0 去 SM 0
Block 1 去 SM 1
Block 2 去 SM 0
这是硬件调度器自动做的。
这个地方就要针对硬件级别进行优化。
Warp 是什么 #
Warp 是 GPU 硬件调度和执行的最小物理单元,通常包含 32 个 Thread。
也就是说,你写的是 Thread,但 GPU 不会真的一个 thread 一个 thread 调度,它会把 thread 打包成 Warp。
比如你写:
kernel<<<1, 256>>>(...);
意思是:
1 个 Block
256 个 Thread
硬件会把这 256 个 Thread 分成:
256 / 32 = 8 个 Warp
也就是:
Warp 0: thread 0 ~ 31
Warp 1: thread 32 ~ 63
Warp 2: thread 64 ~ 95
...
Warp 7: thread 224 ~ 255
你不用手动创建 Warp。
Warp 是硬件自动形成的。
- Thread 是你写代码时看到的逻辑单位
- Warp 是硬件真正调度执行的单位
最好尽量让 CUDA 线程组织"契合 Warp" —— 32 的倍数,假如 33:
Thread 0 ~ 31 → Warp 0,满的
Thread 32 → Warp 1,只有 1 个有效线程
SP 又是什么 #
Warp 最终在 SM 内部的执行单元上执行;GPU 内部会把 Warp 的指令发给执行单元去算。
所以关系是:
你控制:Grid / Block / Thread
硬件控制:Block 放到哪个 SM,Thread 怎么组成 Warp,Warp 怎么用 SP 执行
大致映射关系是:
一个 Kernel 启动一个 Grid
一个 Grid 包含很多 Block
一个 Block 会被调度到某个 SM 上执行
一个 Block 里的 Thread 会被硬件切成多个 Warp
Warp 才是硬件真正调度执行的单位
Warp 内的指令最终由 SM 内部执行单元完成
CUDA 软件模型:
Grid
└── Block
└── Thread
GPU 硬件执行模型:
GPU
└── SM
└── Warp
└── 各种 Core / 执行单元
最重要的是:
Block → SM
Thread → Warp
这不是手动指定的,是硬件自动安排的。
全局坐标计算 #
一维坐标计算 #

一维数组 kernel,基本都是这个模板:
__global__ void kernel(float* x, float* y, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
// 一定要写边界,可能会出现空余的线程 (比如 3x4 > 10)
if (i < N) {
y[i] = ...;
}
}
主机端启动:
int blockSize = 256;
int gridSize = (N + blockSize - 1) / blockSize; // 向上取整,覆盖所有的数据
kernel<<<gridSize, blockSize>>>(x, y, N);
二维坐标计算 #
二维数据常见于图像、矩阵和二维 Tensor。
比如一张图像有:
width = 图像宽度,也就是每一行有多少个像素
height = 图像高度,也就是一共有多少行
二维 kernel 里通常先计算当前线程负责的列和行:

// 列方向,当前块之前的数量 * 每块宽度 + 当前块内的线程偏移
int col = blockIdx.x * blockDim.x + threadIdx.x;
// 行方向,当前块之前的数量 * 每块高度 + 当前块内的线程偏移
int row = blockIdx.y * blockDim.y + threadIdx.y;
但是内存本质是一维连续空间,不是真正的二维格子。
所以还要把二维坐标 (row, col) 转成一维线性地址:
// 我们只需要利用行优先规则转换
if (row < height && col < width) {
int global_idx = row * width + col; // 转为一维线性地址
}
这里的关键是:
width 是每一行有多少个元素。
row * width 表示跳过前面 row 行。
+ col 表示当前行内部的列偏移。
例如:
width = 4
height = 3
二维数据可以看成:
第 0 行: (0,0) (0,1) (0,2) (0,3)
第 1 行: (1,0) (1,1) (1,2) (1,3)
第 2 行: (2,0) (2,1) (2,2) (2,3)
如果当前线程负责:
row = 2
col = 1
那么一维下标是:
global_idx = row * width + col;
= 2 * 4 + 1;
= 9;
在 CUDA 里,坐标计算不仅影响代码是否正确,也会影响性能。
一个很重要的黄金法则是:
让 x 维度的线程连续访问连续的内存地址。
原因是:在 CUDA 中,一个 Warp 通常包含 32 个 Thread,而这些 Thread 在线程编号上是连续的。对于二维 Block 来说,Warp 内的线程通常会优先沿着 threadIdx.x 方向连续排列。
也就是说,如果我们这样写:
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int idx = row * width + col;
那么同一个 Warp 内相邻的 Thread 很可能访问:
thread 0 -> data[row * width + col + 0]
thread 1 -> data[row * width + col + 1]
thread 2 -> data[row * width + col + 2]
...
thread 31 -> data[row * width + col + 31]
这些地址在内存中是连续的。
这对 GPU 非常友好,因为相邻 Thread 访问相邻地址时,GPU 可以更高效地合并这些 global memory 访问,也就是所谓的 coalesced memory access.
因此,对于行优先存储的数据,比如 C/C++ 数组、图像、矩阵、PyTorch contiguous tensor,通常应该让:
x / col 方向对应内存中连续变化的维度
也就是让 threadIdx.x 负责访问连续的列方向。
例如二维图像中,推荐:
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int idx = row * width + col;
而不是让相邻线程跨行、跨 stride 访问:
int idx = col * height + row; // 对行优先数据通常不友好
可以把这个规则记成一句话:
CUDA 里不仅要让线程“算对自己的位置”,还要让相邻线程“访问相邻的数据”。
这就是为什么二维图像处理中常见的 Block 配置会选择:
dim3 block(16, 16);
或者:
dim3 block(32, 8);
它们的总线程数都是 256,都是 32 的倍数,能比较好地契合 Warp。
其中 32 × 8 的好处是:x 方向正好有 32 个线程,一个 Warp 更容易覆盖一整段连续的列方向数据,因此在行优先内存布局下更容易形成连续访存了;
哪怕是(16, 16),Warp 大小固定为 32 个 threads ,实际上:
Warp0:
row0 + row1
Warp1:
row2 + row3
Warp2:
row4 + row5
... ...
threadIdx.x/y/z 是程序员视角的坐标;Warp 划分依据的是线性线程编号(linear thread id)。
所以,全局坐标计算的最终目标不只是知道自己处理哪个元素
还要进一步做到:
让相邻线程处理相邻元素
这就是后续 CUDA kernel 优化的起点。
CUDA Memory Hierarchy #
CUDA 内存管理可以分为这五个方面:
Thread 私有:
Register
Local Memory
Block 共享:
Shared Memory
全 GPU 共享:
L2 Cache
Global Memory / HBM
特殊只读:
Constant Memory
Texture / Read-only Cache
CPU 侧:
Host Memory
NVIDIA 官方文档里也把 shared memory 描述为 block 内线程共享、生命周期随 block;global memory 对所有线程可见,constant/texture 是额外的只读空间。Shared memory 通常比 global memory 快很多,常被当作程序员手动管理的 cache.

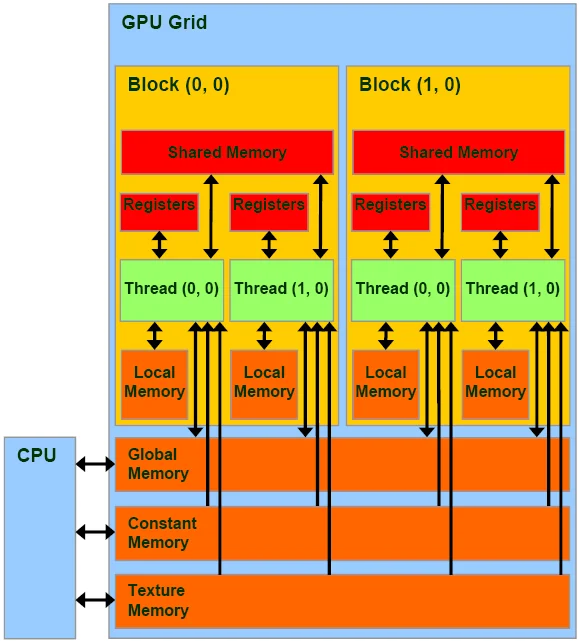
GPU 的高效率来自于高并行,借助 GPU 内部大量的 SM 并行单元,可以同时处理各种类型(加法乘法、矩阵计算、以及一些其他的比如指数),提升计算效率。
但仅有并行是远远不够的,随着技术的不断发展,制约其效率的重心悄悄移动到了 memory 的低效率应用上。GPU 的计算单元很强,但从 HBM/global memory 取数据延迟很高;优化 kernel 的核心通常是减少慢内存访问(更合理的寄存器分配、共享内存使用、显存调度等多方面)、提高数据复用。
第一层:Register #
Register 是每个 thread 私有的最快存储。
比如:
float sum = 0.0f;
这里的 sum 通常会放在 register 里。它的速度是最快的,作用域和生命周期仅局限于单个 thread 与其执行期间,也就只有这个 thread 内部可以访问。
以最简单的加法算子为例,
__global__ void add(float* a, float* b, float* c) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
float x = a[i]; // x 通常进 register
float y = b[i]; // y 通常进 register
float z = x + y; // z 通常也在 register
c[i] = z;
}
执行过程中,按顺序:
HBM/global memory 里的 a[i], b[i]
↓
读到 register
↓
做加法计算
↓
写回 HBM/global memory
kernel 里,比如 LayerNorm、RMSNorm、GEMM 的 accumulator,经常就是放在 register 里。
第二层:Local Memory #
实际上 Local Memory 通常在 global memory 里。比如一个数组太大,register 放不下,编译器可能把它 spill 到 local memory;或者每个 thread 用太多 register,register 不够,也可能 spill。
所以,Local Memory 这个名字有点迷惑:
local 指的是“每个 thread 私有”
不是指“它一定离 thread 很近”
(Local Memory 通常意味着 register spill,性能可能变差。)
第三层:Shared Memory #
Shared Memory 是一个 block 内所有 thread 可以共享的内存。
写法参考:
__shared__ float tile[256];
速度也很快,同一个 block 的 thread 都能访问,作用域和生命周期仅局限于这个 block 与其执行期间。
最典型的用途,把 global memory 中会被反复使用的数据,先搬到 shared memory ,然后 block 内线程重复使用。这也就是 GEMM tiling 的基础
矩阵乘法:
C = A x B
如果每个 thread 都直接从 global memory 读 A 和 B,读写效率会很慢。 更好的方式是:
A tile 从 global memory 搬到 shared memory
B tile 从 global memory 搬到 shared memory
↓
很多 thread 重复使用这些 tile
↓
算完一小块 C
这也是 FlashAttention 快的核心思想之一:减少反复读写 HBM,把中间数据尽量留在片上内存里。
第四层:L1 Cache #
L1 Cache 在 SM 附近,访问比 global memory 快,但它不像 shared memory 那样完全由程序员手动管理。
可以先这样理解:
Shared Memory:程序员显式搬数据、显式复用
L1 Cache:硬件自动缓存近期访问过的数据
比如一个 kernel 反复访问某一小段 global memory,硬件可能会把这部分数据留在 L1 Cache 里。之后同一个 SM 上的 thread 再访问这些数据时,就不一定每次都要跑到 HBM/global memory 去拿。
但是 L1 Cache 有几个限制:
- 容量有限
- 行为由硬件决定
- 不保证每次都命中
- 不适合依赖它来表达明确的数据复用逻辑
所以在写 CUDA kernel 时,L1 Cache 更像是一个“自动帮忙”的层级,而 shared memory 更像是一个“程序员主动设计”的层级。
对于简单的逐元素操作:
c[i] = a[i] + b[i];
每个元素通常只读一次、用一次,L1 Cache 能帮的忙有限。
但对于有局部性的数据访问,比如卷积、stencil、矩阵块计算,L1 Cache 和 shared memory 都可能发挥作用。
区别在于:
如果数据复用模式很明确,而且多个 thread 要共享同一批数据:
优先考虑 shared memory
如果只是普通读取,或者复用模式不适合手动搬运:
交给 L1 / L2 cache
第五层:L2 Cache #
L2 Cache 比 L1 更远一些,但它是整个 GPU 共享的 cache。
也就是说:
L1 Cache:更靠近单个 SM
L2 Cache:多个 SM 共享
Global Memory / HBM:真正的大容量显存
如果一个 block 在某个 SM 上读过一段 global memory,数据可能进入 L2 Cache。之后另一个 SM 上的 block 如果也读到相近数据,就有机会从 L2 Cache 命中,而不是重新从 HBM 读取。
这在多个 block 处理相邻数据时比较重要。
例如图像处理里,两个 block 可能分别处理相邻区域:
Block 0 处理第 0 ~ 15 行
Block 1 处理第 16 ~ 31 行
如果算法需要访问边界附近的数据,那么相邻 block 之间可能会读取到重叠区域。这个时候 L2 Cache 就可能减少一部分 HBM 访问。
不过和 L1 一样,L2 Cache 也是硬件自动管理的。我们一般不会在入门阶段直接控制它,而是通过更合理的访问模式让 cache 更容易发挥作用。
比如:
连续访问
重复访问
减少随机访问
减少不必要的跨 stride 访问
这些都会让 cache 机制更有机会工作。
第六层:Global Memory / HBM #
Global Memory 就是我们平常说的 GPU 显存里的主要数据区域,底层通常对应 HBM。
它的特点是:
容量大
所有 thread 都能访问
生命周期可以跨 kernel
访问延迟高
带宽很高,但需要正确的访问方式才能吃满
在主机端用 CUDA API 分配 device memory,通常就是在 global memory 上分配:
float* d_a;
float* d_b;
float* d_c;
cudaMalloc(&d_a, N * sizeof(float));
cudaMalloc(&d_b, N * sizeof(float));
cudaMalloc(&d_c, N * sizeof(float));
kernel 里传进去的 a, b, c 指针,通常指向的就是这块 device global memory:
__global__ void add(float* a, float* b, float* c, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < N) {
c[i] = a[i] + b[i];
}
}
这里每个 thread 都会:
从 global memory 读 a[i]
从 global memory 读 b[i]
把结果写回 global memory 的 c[i]
这个 kernel 的计算量很少:
1 次加法
2 次读
1 次写
所以它通常不是被计算能力限制,而是被 memory bandwidth 限制。
也就是说,GPU 的核心可能还没有忙满,瓶颈就已经在“搬数据”上了。
这类 kernel 常被称为 memory-bound kernel。
与之相对,如果一个 kernel 对每次读入的数据做了大量计算,比如矩阵乘法里一个元素参与很多次乘加,那么它可能更接近 compute-bound。
优化 global memory 访问时,最重要的还是前面已经提到的连续访存:
让同一个 Warp 里的相邻 thread 访问相邻地址
比如:
int i = blockIdx.x * blockDim.x + threadIdx.x;
c[i] = a[i] + b[i];
同一个 Warp 里的 thread 会访问:
a[0], a[1], a[2], ... a[31]
这些地址是连续的,GPU 可以把这些访问合并成更高效的 memory transaction。
如果访问变成:
a[0], a[1024], a[2048], ...
每个 thread 都跳很远,访存就会变得不友好。
特殊只读内存:Constant Memory #
Constant Memory 适合存放所有 thread 都会读取、但不会修改的小数据。
比如:
卷积核参数
一些固定系数
小型查表数据
写法上可以使用 __constant__:
__constant__ float kernel_weight[9];
它的特点是:
GPU 端只读
容量较小
适合所有 thread 读取相同地址
如果一个 Warp 里的所有 thread 都读取同一个 constant memory 地址,那么这种访问会非常高效。
但如果每个 thread 都读不同地址,constant memory 的优势就会下降。
所以它适合这种模式:
所有 thread 都用同一组小参数
不适合这种模式:
每个 thread 都随机读取不同位置的大数组
特殊只读路径:Texture / Read-only Cache #
Texture Memory 最早更多是为图形纹理访问设计的,但在 CUDA 里也可以用来优化某些只读数据访问。
它适合:
只读数据
二维/三维空间局部性较强的数据
访问模式不完全连续,但附近元素会被反复访问
比如图像处理中,一个 thread 处理某个像素时,可能会访问它周围的一圈邻居:
(row - 1, col - 1) (row - 1, col) (row - 1, col + 1)
(row, col - 1) (row, col) (row, col + 1)
(row + 1, col - 1) (row + 1, col) (row + 1, col + 1)
这种访问不是单纯的一维连续读取,但有明显的空间局部性。
现代 CUDA 里很多普通只读访问也可以通过 read-only cache 路径优化。入门阶段不需要马上纠结 texture 细节,只要先记住:
普通大数组读写:
global memory
小型只读常量:
constant memory
具有空间局部性的只读数据:
texture / read-only cache 可能有帮助
CPU 侧:Host Memory 和 Device Memory #
CUDA 程序通常同时涉及 CPU 和 GPU 两侧的内存。
可以先分成:
Host Memory:
CPU 侧内存,也就是普通程序里的内存
Device Memory:
GPU 侧内存,也就是 cudaMalloc 分配出来的显存
最常见的数据流程是:
float* h_a = new float[N];
float* h_b = new float[N];
float* h_c = new float[N];
float* d_a;
float* d_b;
float* d_c;
cudaMalloc(&d_a, N * sizeof(float));
cudaMalloc(&d_b, N * sizeof(float));
cudaMalloc(&d_c, N * sizeof(float));
cudaMemcpy(d_a, h_a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(float), cudaMemcpyHostToDevice);
add<<<gridSize, blockSize>>>(d_a, d_b, d_c, N);
cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost);
也就是:
CPU 准备数据
↓
拷贝到 GPU
↓
GPU kernel 计算
↓
结果拷贝回 CPU
这里要注意,CPU 和 GPU 之间的数据传输通常比 GPU 内部 HBM 访问更慢。
更好的思路是:
尽量一次拷贝较大批数据
尽量让数据在 GPU 上多停留一会
尽量连续跑多个 kernel 后再拷贝回 CPU
PyTorch 里也有类似现象:
x = x.cuda()
y = model(x)
y = y.cpu()
如果在训练或推理过程中频繁 .cpu() / .cuda(),性能会明显变差,因为这会不断触发 CPU 和 GPU 之间的数据搬运。
Unified Memory 简单理解 #
CUDA 还有一种 Unified Memory,可以用 cudaMallocManaged 分配:
float* x;
cudaMallocManaged(&x, N * sizeof(float));
这种内存 CPU 和 GPU 都能通过同一个指针访问。
它让代码写起来更简单:
CPU 可以读写 x
GPU kernel 也可以读写 x
但简单不代表一定最快。
因为底层仍然要处理数据到底在 CPU 侧还是 GPU 侧的问题。如果访问模式不合理,就可能发生 page migration,也就是数据在 CPU 和 GPU 之间来回迁移。
优化 Memory 到底在优化什么 #
CUDA kernel 优化里,memory 部分大概可以归纳成三件事。
- 第一,减少慢内存访问:
能放 register 的中间变量,不要反复写回 global memory; 能在 shared memory 复用的数据,不要每个 thread 都反复从 HBM 读; 能留在 GPU 上的数据,不要频繁搬回 CPU;
- 第二,提高 global memory 访问效率:
让相邻 thread 访问相邻地址; 让数据尽量连续; 减少随机访问和大 stride 访问;
- 第三,提高数据复用:
一次从 HBM 读进来的数据,最好参与多次计算;