这段时间在鸭大暑研,时间比较清闲。没事就不由自主多读完了几篇论文。有空的话我就多记录一下吧。
平时一般会关注软件工程领域居多,翻一下A会A刊有没有适合的论文。
这篇是关于大模型检测的,来自ISCE25.
I. Introduction
背景与动机:大型语言模型(LLM)如 Codex 和 ChatGPT,通过在海量代码语料上训练,能够生成语法和功能均正确的代码,极大提升了软件开发的效率与创新能力。然而,这也带来了“人机代码混淆”问题:无法轻易区分代码是人类还是机器所写,进而导致代码归属混淆、漏洞追责困难、工作量评估失真等诚信与安全风险。由于过度依赖其感知的鲁棒性,机器生成的代码中的潜在漏洞可能被忽视。其中真正的作者身份和创建软件制品所投入的努力变得模糊不清。解决这些问题对于维护透明和安全的软件开发生命周期至关重要。
基于扰动的检测方法,如DetectGPT,在识别机器生成文本方面取得了最先进的结果:通过比较原始文本及其各种LLM扰动变体之间的似然分数差异来进行检测。
然而,这种针对自然语言文本的检测方法在应用于代码时面临挑战,因为代码需要严格遵守句法规则,而自然语言可以保持更多变异性。这种情况突显了现有研究中的一个重大差距:缺乏对机器和人类编写代码的内在特征的深入评估,这对于理解机器生成代码的独特模式和制定有效的检测方法至关重要。
在这篇论文中,我们从三个方面对机器编写和人工编写的代码的差异性模式进行了比较分析,包括词汇多样性、简洁性和自然性。通过我们的分析,我们发现与人类相比,机器倾向于编写更加简洁和自然的代码,其标记范围较窄,并遵循常见的编程范式,这种差异在风格标记,如空白标记中更为明显。
提出了一种名为DetectCodeGPT的新方法,用于检测机器编写的代码。我们通过战略性地插入风格化标记,扩展了DetectGPT的基于扰动的框架:针对性地插入空格与换行的“样式扰动”策略,以捕捉机器生成代码在空白字符等方面的刻板模式,实现无需外部模型、零样本的高效检测。
为了评估DetectCodeGPT的有效性,我们在两个数据集上对六个代码语言模型进行了广泛的实验。结果表明,DetectCodeGPT在AUROC这个指标上显著优于最先进的方法,证明是一种无模型且对模型差异鲁棒的方法。
本文贡献:
- 首篇对LLM生成的代码的独立模式进行全面深入分析。进一步推进LLM在编程中应用的重要见解。
- 提出了一种检测机器生成代码的新方法。
- 在多种设置下广泛评估了DetectCodeGPT,并展示了我们方法的有效性。
II. BACKGROUND
A. Large Language Models for Code
基于 Transformer 解码器的大语言模型在自然语言处理任务中取得了显著的成功。在代码生成领域, Codex 和 AlphaCode 是训练大型语言模型在代码上的开创性工作。后来,为增强模型的代码理解与生成能力,研究者提出了“填空式中段”( fill-in-the-middle )预训练任务,以及基于指令的微调方法。最新一代模型( ChatGPT 、 LLaMA )在编程语言与自然语言上同时预训练,进一步提升了跨语言的代码生成效果。
B. Perturbation-Based Detection of Machine-Generated Text
| 在机器生成文本检测领域,基于扰动的 DetectGPT 方法已成为最先进的技术。核心思想是:对机器生成的文本 x 施加微小扰动 $q(\cdot | x)$ 得到 $\widetilde{x}$ 时,其对数概率 $\log p_\theta(x)$ 的下降幅度要明显大于人类文本。这是因为机器生成的文本通常更可预测、更贴合训练模式,因此在扰动下会表现出明显的负曲率(log 概率急剧下降)。相比之下,人类撰写的文本具有更丰富多样的风格,反映了多元的经验与认知过程,所以在相同扰动下,人类文本的 $\log p_\theta(x)$ 不会出现如此剧烈的下降。 |
对原始文本(或代码)片段 $x$ 应用微小扰动——如使用 T5 模型做掩码语言模型(MLM)随机替换若干 token——得到一组扰动版本 $\widetilde{x}$
分别计算原始片段和每个扰动片段在同一语言模型下的对数概率 $\log p_{\theta}(x)$ 和 $\log p_\theta(\widetilde{x})$ ,取扰动前后对数概率的期望差值:
\(\mathrm{\textbf{d}}(x,p_{\theta},q) \triangleq \log p_{\theta}(x) - \mathbb{E}_{\widetilde{x}\sim q(\cdot |x)} \log p_{\theta}(\widetilde{x})\)

III. EMPIRICAL ANALYSIS
A. Study Design:三项指标
- Lexical Diversity:在编程的背景下,这指的是变量名、函数、类和保留字的多样性。有四个重要的经验指标Token Frequency(Token 频率)、Syntax Element Distribution(语法元素分布,tree-sitter 2分析)、Zipf’s and Heaps’ Law(Zipf’s: 在一个语料库中,词(或 token)出现频率与其频率排名的反比关系;Heaps ’: 随着代码样本越来越多,“不同 token 的种类”会以一个小于线性的速率增长)

-
Conciseness: Number of tokens 、Number of lines
-
Naturalness: Token Likelihood and Rank,计算每段代码的对数似然(log-likelihood)和在候选生成列表中的平均排名(rank)。

B. Experimental Setup
CodeLlama-7B, p=0.95, 测试了T = 0.2 和 T = 1.0捕捉模型在不同设置下的行为。所有实验均在配备24GB内存的2块NVIDIA RTX 4090 GPU上进行。
C. Dataset Preparation
人类代码采样随机从 CodeSearchNet 语料库中抽取 10,000 个 Python 函数;使用函数签名及其伴随的注释作为模型prompt,调用各大模型(如 CodeLlama、ChatGPT 等)生成函数体,即可得到一一对应的人类与机器版本代码对。
选择它是因为 CodeSearchNet 来自真实开源项目,覆盖范围广、难度与实用场景贴近;
D. Results and Analysis
-
Token Frequency: 针对T=0.2时生成的机器代码,与人类编写的代码,各自列出了出现频率最高的前 50 个 token:
共性:基础语法的一致性,都频繁使用“.”、“(”、“)”等标点,以及“if”、“return”、“else”等基本结构关键字,因为这些是所有 Python 代码必须遵循的语法骨架。
差异:错误处理、面向对象习惯,多使用样板,可能源于模型学习到的模板化写法。

Finding 1: Machine-authored code pays more attention to exception handling and object-oriented principles than human, suggesting an emphasis on error prevention and adherence to common programming paradigms.
-
Syntax Element Distribution: “keyword”(关键字)、“operator”(运算符)、“syntactic symbols”(语法符号)、“whitespace”(空白符)这四大类,在人机代码中所占比例几乎相同,表明两者在基础语法骨架上高度一致。
细微差别(卡方检验 p<0.01 显著):
标识符(Identifier):机器生成的代码中,标识符所占比例显著低于人类代码,机器倾向于用更少的变量/函数名,更压缩的方式组织代码。
字面量(Literal):机器代码字面量(如数字、字符串常量等)比例略高,表明模型可能更直接地在代码里硬编码数据值,这可能源于它在大量数据处理任务上训练的习惯。
注释(Comment):在温度 T=1.0 下,机器生成代码的注释占比显著增多,反映出当模型输出更随机、探索性更强时,更倾向于“自我解说”或添加文档说明。

Finding 2: Machine-authored code tends to use fewer identifiers, more literals for direct data processing, and have more comments when the generation temperature grows.
-
Zipf’s and Heaps’ Laws: Zipf在代码领域同样适用。T=0.2时,机器生成的代码在排名大约第 10–100 的中频词元上使用得更集中,表明模型在低温度下更倾向于选择那些“既常见又稳妥”的中频词。也类似Heaps趋势,机器代码(尤其T=0.2)的增长曲线斜率更平缓,意味着它引入新词元的速度更慢,词汇多样性更低。
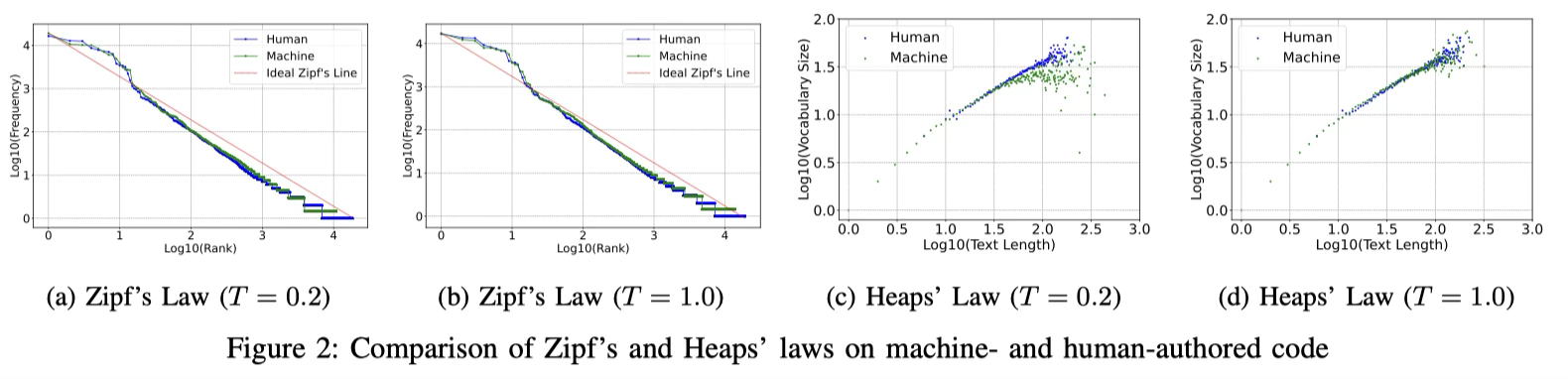
Finding 3: Machines demonstrate a preference for a limited spectrum of frequently-used tokens, whereas human code exhibits a richer diversity in token selection.
- **Number of Tokens and Lines: **机器生成的代码在 token 总数和行数上都显著少于人类代码,表现出更强的“简洁倾向”。随着温度提高,模型生成的代码风格变得更具多样性——分布曲线向人类代码靠拢。
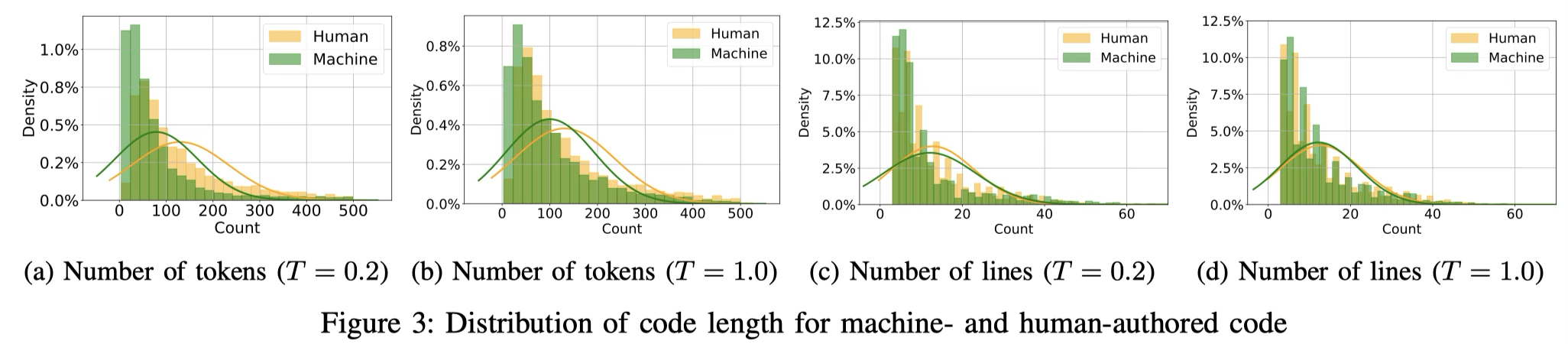
Finding 4: Machines tend to write more concise code as instructed by their training objective, while human programmers tend to write longer code, reflective of their stylistic preferences.
- Token Likelihood and Rank: 机器生成的代码两个指标都更优,说明从模型自身的视角看,机器生成的代码更符合预测偏好更“自然”;空白符(whitespace)的自然性差异最为显著,人类的空白使用更具个人风格—不同的缩进宽度、行末空格、注释对齐等习惯差异更大。
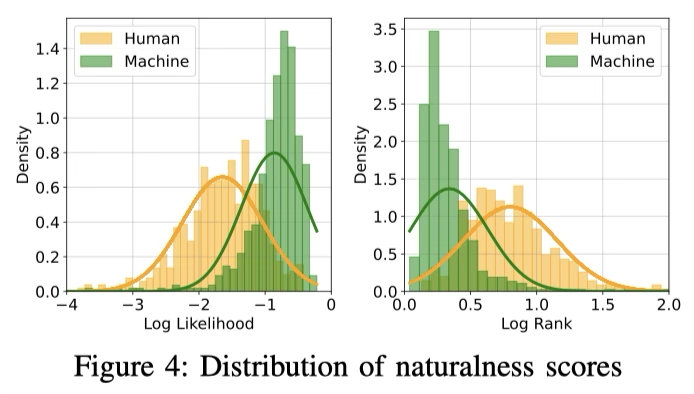
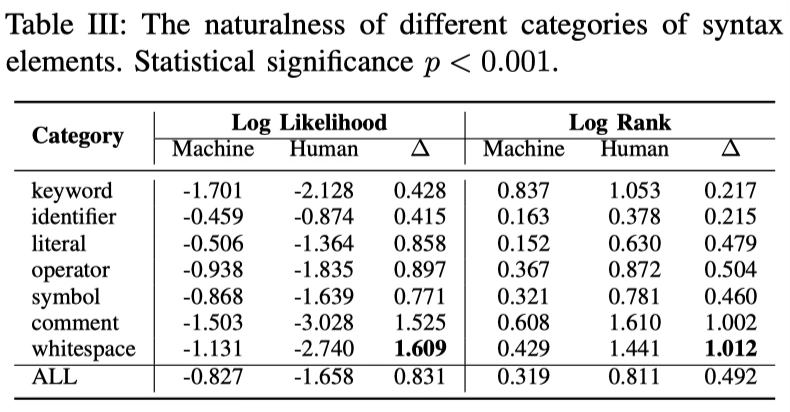
Finding 5: Machine-authored code exhibits higher “naturalness” than human-authored code, and the disparity is more pronounced in tokens such as comments, and whitespaces, which are more reflective of individual coding styles.
IV. DETECTING MACHINE GENERATED CODE
实证结果表明,机器倾向于使用更简洁、更自然的代码,其标记范围较窄,遵循常见的编程范式,这种差异在风格化标记(如空白符)方面更为明显。这激发了一个新的想法来检测机器编写的代码:我们不是干扰任意的标记,而是专注于干扰那些最能表征机器偏好的风格标记。基于这个想法,我们引入了DetectCodeGPT,这是一种用于检测机器编写代码的新型零样本方法。
A. Problem Formulation
| 我们将机器生成的代码检测定义为分类任务,预测给定的代码片段 $x$ 是否由源模型 $p_\theta$ 生成。为此,我们通过扰动过程 $q(\cdot | x )$ 将$x$转换为等价形式 $\widetilde{x}$ . 我们预计如果$x$是由LLM编写的,其自然度得分将急剧下降。这里的关键问题是如何定义自然度得分以及如何设计扰动过程。 |
B. Measuring Naturalness
以往方法常用 token 的对数似然(log likelihood)来评估文本或代码的自然性;但在判别机器 vs. 人类内容时,对数排名(log rank) 更平滑、鲁棒,效果更好。
与直接计算标记对数似然的DetectGPT不同,我们采用归一化扰动对数秩(NPR)得分来捕捉自然度。NPR得分正式定义为: \(\mathbf{NPR}\left(x,p_\theta,q\right)\triangleq\frac{\mathbb{E}_{\tilde{x}\thicksim q(\cdot|x)}\log r_\theta\left(\tilde{x}\right)}{\log r_\theta(x)},\) 直观上,如果 本身“更自然”(期望是机器偏好),那么扰动后排名变化(logr 变大)的幅度相对更明显,从而使比值更大。
C. Perturbation Strategy
我们的实证研究表明,空白( whitespace ) tokens 作为机器正则化和人类多样性的重要指标,指向编码风格的固有差异。因此,我们提出了一种高效有效的扰动策略,以下列出了两种扰动类型。关于这些扰动的有效性的详细解释见第六部分A节。
Space Insertion(空格插入):
| 令 $C$ 为代码中所有可插入空格的位置集合。随机选取一个子集 $C_s \subseteq C$ 使得 $ | C_s | = \alpha \times | C | $ ,对每个位置 $c \in C_s$ ,插入 $n_{\mathrm{spaces}}(c)$ 个空格,其中 $n_{\mathrm{spaces}}(c)$ 服从参数为 $\lambda_{\mathrm{spaces}}$ 的泊松分布。 |
泊松分布模拟“人类往往随机、忽略式地插入少量空格”的行为。论文实验中取 $\lambda_{\mathrm{spaces}} = 3$ \(n_{\mathrm{spaces}}(c)\sim\mathcal{P}(\lambda_{\mathrm{spaces}}).\)
C. Newline Insertion(换行插入):
| 将代码按行划分为集合 $L$ ,随机选取子集 $L_{n}\subseteq L$ ,使得 $ | L_n | = \beta\times | L | $ . 对每个被选中的行 $l$ ,插入 $n_{\mathrm{newlines}}(l)$ 个额外空行,服从参数 $\lambda_{\mathrm{newlines}}$ 的泊松分布。 |
模拟人类有时随意地空出一两行的风格, $\lambda_{\mathrm{newlines}} = 2$ \(n_{\mathrm{newlines}}(c)\sim\mathcal{P}(\lambda_{\mathrm{newlines}}).\) 我们随机选择空格或换行其中一种扰动方式,对原始片段 $x$ 做 $k$ 次独立扰动,得到 ${\tilde{x}i}{i=1}^k$ .( 后面文章设置 $k = 50$ ),这样能够在细粒度的“风格”层面引入随机性,放大人与机器在空白使用上的差别。

V. EVALUATION
进行实验以评估DetectCodeGPT的有效性:
- RQ1: 检测方法能在多大程度上,将机器生成的代码和人类编写的代码区分开?
- RQ2: 方法里的各个组成部分各自对最终效果有多大影响?
- RQ3: 改变扰动数量的影响对检测性能有何影响?
- RQ4: 我们的跨模型代码检测方法有多有效?
A. Datasets
与实证研究中使用的不同,选择来自 The Stack 的 Python 代码作为另一个评估数据集,提供了来自各种开源项目的代码,这些项目代表了现实世界的场景。使用该数据集的解析和过滤版本,并将函数定义与其相应的注释作为提示。对于每个数据集和模型的组合,采样500个人工和机器代码对进行评估。代码的最大长度被修剪到128个tokens。
B. Studied Models
选取了多款主流的开源代码生成大模型作为“机器”来源,包括 Incoder、Phi-1、StarCoder、WizardCoder、CodeGen2 以及 CodeLlama;它们的模型权重都从 Huggingface 获取,并且覆盖了从 1B 参数到 7B 参数的多种规模,以保证评估结果具有代表性和广泛性。
C. Evaluation Metric
沿用前人的做法,选取 ROC 曲线下面积(AUROC) 作为衡量 DetectCodeGPT 整体性能的核心指标。 \(\mathrm{AUROC} = \int_{0}^{1}\mathrm{TPR}(t) \mathrm{d} t\) TPR ( TP / TP + FN ) 真正率:被正确识别为机器的样本 / 总样本
FPR 同理。
D. Baselines
Log p(x) :用源模型对每个 token 的对数概率平均值,分数越高表示模型越偏好该代码片段
Entropy:将源模型在生成每个 token 时的平均预测熵(entropy)作为判别依据:若一段代码在模型眼中分布更尖锐(熵更低),则更可能是机器生成;反之熵更高则偏向人写 。
(Log-) Rank:统计每个 token 在模型输出分布中的排名(或对数排名)的平均值,机器生成的代码因更符合模型偏好,通常平均 rank/log rank 更小 。
DetectGPT:通过对原始代码和其“掩码后重建”版本计算 log p 的差值(perturbation discrepancy gap),基于掩码恢复对机器代码造成的概率跌幅更大来判别机器生成 。
DetectLLM:在 DetectGPT 基础上做两种改进:LRR、NPR,结合概率和排名信息,并且对扰动效果做归一化,比单一度量更稳、更准。
GPTSniffer:一个监督基础模型:在每种生成模型与解码设置下,各采样 1000 条示例(机器 vs. 人类),按照 OpenAI RoBERTa GPT 检测器的思路进行微调,让它学习从代码特征里直接判断作者。
E. Experimental Setup
代码生成统一使用 Top-p 采样(p=0.95),分别测试两种温度:T=0.2 和 T=1.0. 最大生成长度限制为 128 个 token。
空格插入比例、换行插入比例 $\alpha,\beta = 0.5$ , $\lambda_{\mathrm{spaces}}=3$ , $\lambda_{\mathrm{newlines}}=3$ , $k = 50$ .
DetectGPT 与 DetectLLM 中需要用模型恢复扰动代码时,选用 CodeT5+(770M)作为恢复模型。
GPTSniffer(有监督) 基线用 CodeBERT:训练 5 个 epoch,批大小 16,学习率 2×10−5,优化器为 AdamW.
实验均在两块 NVIDIA RTX 4090(各 24 GB)GPU 上完成。
-
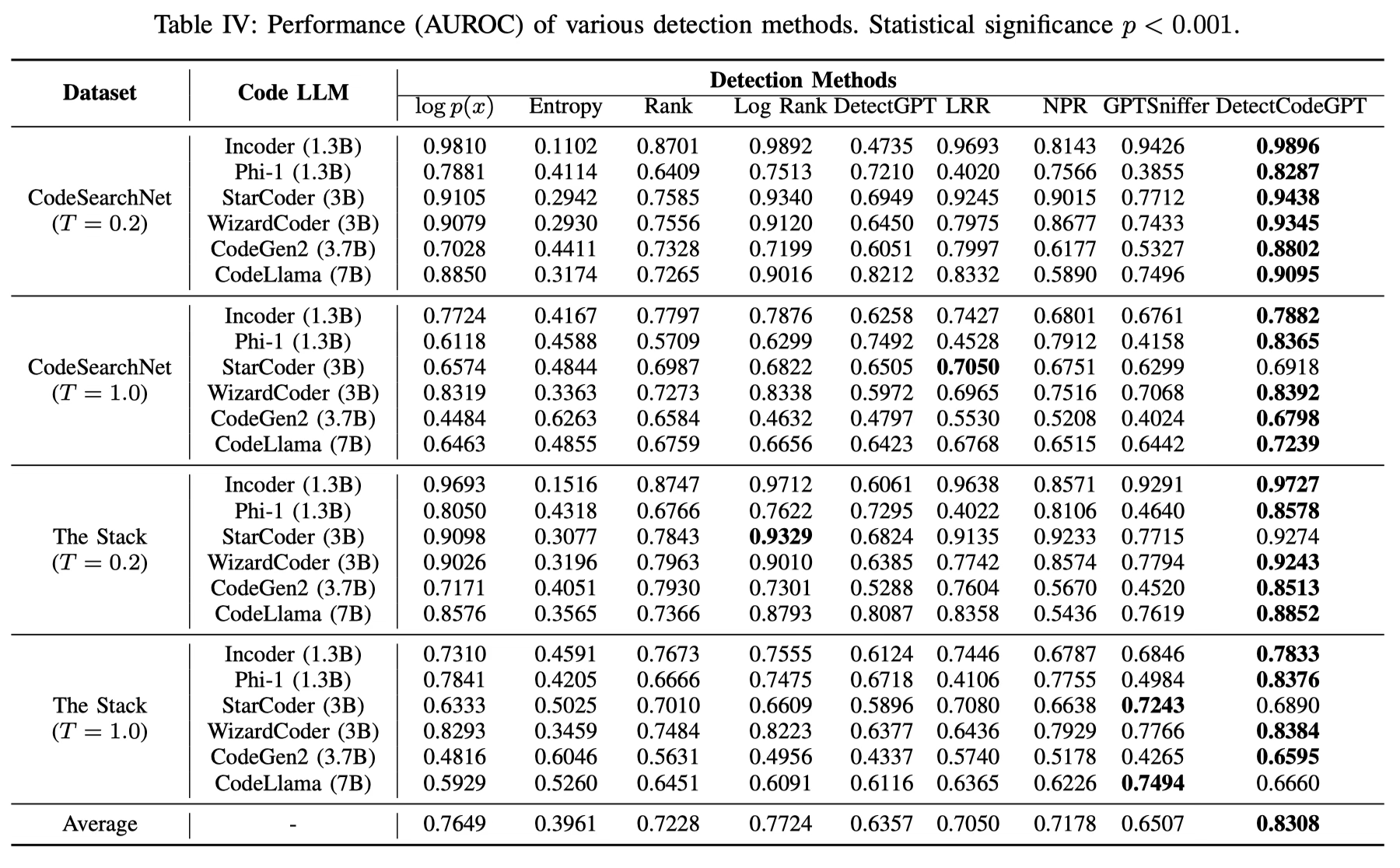
RQ1: Detection Performance
DetectCodeGPT始终优于基线方法。与最强的基线方法Log Rank相比,我们的方法在AUROC上平均提高了7.6%.
我们也重复进行了10次实验,并采用Wilcoxon秩和检验来评估这些方法在性能差异上的统计显著性。结果显示,我们方法在性能上的优越性具有统计学意义,p值小于0.001。在这些不同的设置中实现的高AUROC分数证实了该方法在推广和可靠区分机器生成代码和人工编写代码方面的优越能力。
可以观察到,在温度设置为T=1.0时,检测的挑战明显比T=0.2时增加。这可能是由于在此温度下更高的随机性,模型可能生成具有更多样化风格的输出。尽管这些困难增加了,但提出的方法在检测精度上仍保持领先地位。
值得一提的是,我们的零样本框架通常优于监督式GPTSniffer,突显了使用训练数据依赖的监督模型检测机器生成代码的挑战。

-
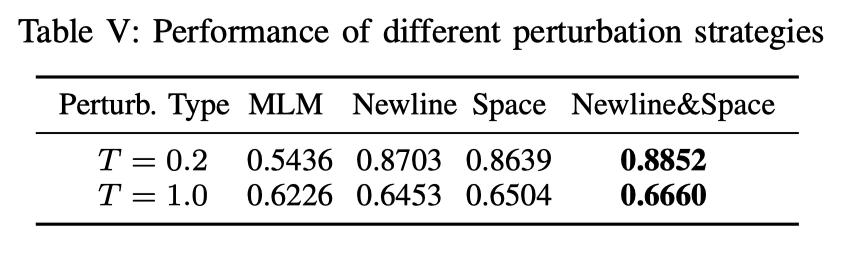
RQ2: Ablation Study
比较了不同扰动策略在The Stack数据集上使用CodeLlama(7B)模型检测机器生成代码的有效性。
-
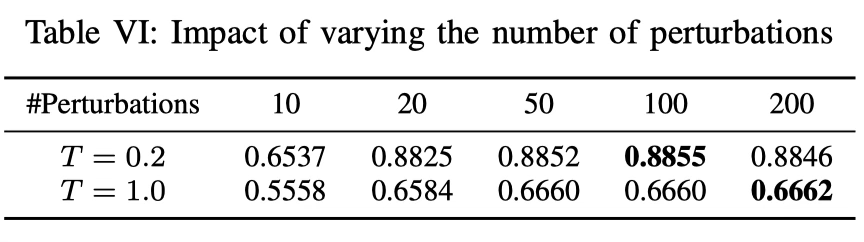
RQ3: Impact of Perturbation Count
随着扰动次数从10增加到20,AUROC得分迅速上升,突显了我们扰动方法的效率。
值得注意的是,增加到20次扰动已经能够产生稳健的检测性能,进一步的增加只会导致微小的改进。这表明,我们的方法只需要相对较少的扰动次数就能有效地区分人类和机器编写的代码。这表明我们的方法不仅有效,而且高效。
-
RQ4: Performance of Cross-Model Code Detection
在 The Stack 数据集、T=0.2 的条件下,对每一种“源模型→检测模型”组合,都用检测模型去算原始代码和扰动代码的 NPR,然后按 DetectCodeGPT 的流程判断“机写/人写”。
其性能在跨模型应用中仅略有下降。
这些结果表明,DetectCodeGPT是一种无模型方法,对模型差异具有鲁棒性,使其成为现实世界应用中可行的解决方案,在这些应用中,源模型可能是未知的或不可访问的。

VI. DISCUSSION
A. Why is DetectCodeGPT Effective?
1)保留代码正确性:DetectGPT中的掩码和恢复扰动容易引入小错误(比如标识符使用不当),使代码无法运行,并对自然度评分产生负面影响。这种代码破解扰动如果是在第二节B中由人类编写,将违反对代码自然度评分影响最小的假设。相比之下,插入换行符和空格在大多数情况下不会影响代码的正确性,从而确保我们方法的有效性。
2)模仿人类随机性:如第三节D5(自然度)所述,人类在风格标记(如空格和换行符)的使用上比机器表现出更少的天赋和更多的随机性。例如,人类程序员可能会根据需要自由地在代码中插入空白符,特别是换行符,而机器程序员通常试图以更标准化和模块化的方式来格式化代码。我们提出的扰动策略模仿了人类对空格和换行符的自由使用,从而使扰动更符合第三节所期望的“随机性”。
B. Strength of DetectCodeGPT
与现有方法相比,DetectCodeGPT消除了对每个LLM多次扰动代码的需求,从而提高了效率。与监督学习相比,DetectCodeGPT凭借零样本学习能力脱颖而出,使其能够在不依赖大量数据集训练的情况下检测机器生成的代码。这种模型无关的优势意味着它可以推广到各种代码LLM中。
C. Limitations and Future Directions
1)由于计算限制,我们只关注7B参数范围内的一组LLMs。随着LLMs领域的快速演变,纳入更多更大型的LLMs可以显著增强我们发现的泛化性和鲁棒性。
2)当前的分析仅集中在Python代码上,而其他编程语言的特征可能没有得到充分探索。不过,根据第六部分B节中对我们方法的分析,我们相信我们的方法可以有效地推广到其他语言,特别是在代码插入换行符和空格后功能不会受到很大影响的情况下,如C/C++、Java和JavaScript.
CONCLUSION
在这篇论文中,我们从代码的三个层面——词汇多样性、简洁性和自然性,对机器编写和人工编写的代码之间的细微差异进行了深入分析。结果表明,机器倾向于编写更加简洁和自然的代码,遵循常见的编程范式,这种差异在诸如空白符等风格化标记上更为明显,这些标记代表了代码的句法分割。基于这些见解,我们提出了一种新的检测方法,DetectCodeGPT,它引入了一种新颖的风格化扰动策略,简单而有效。DetectCodeGPT的实验结果证实了其有效性,展示了其帮助维护代码作者权和完整性的潜力。